
C# HashSet: Everything you need to know
Collection data structures have a major impact on the application performance.
A HashSet is a data structure that is used for high-performance operations. HasSet contains unique elements, so the implementation makes it possible to search through the data faster.
The most important features of a HashSet are:
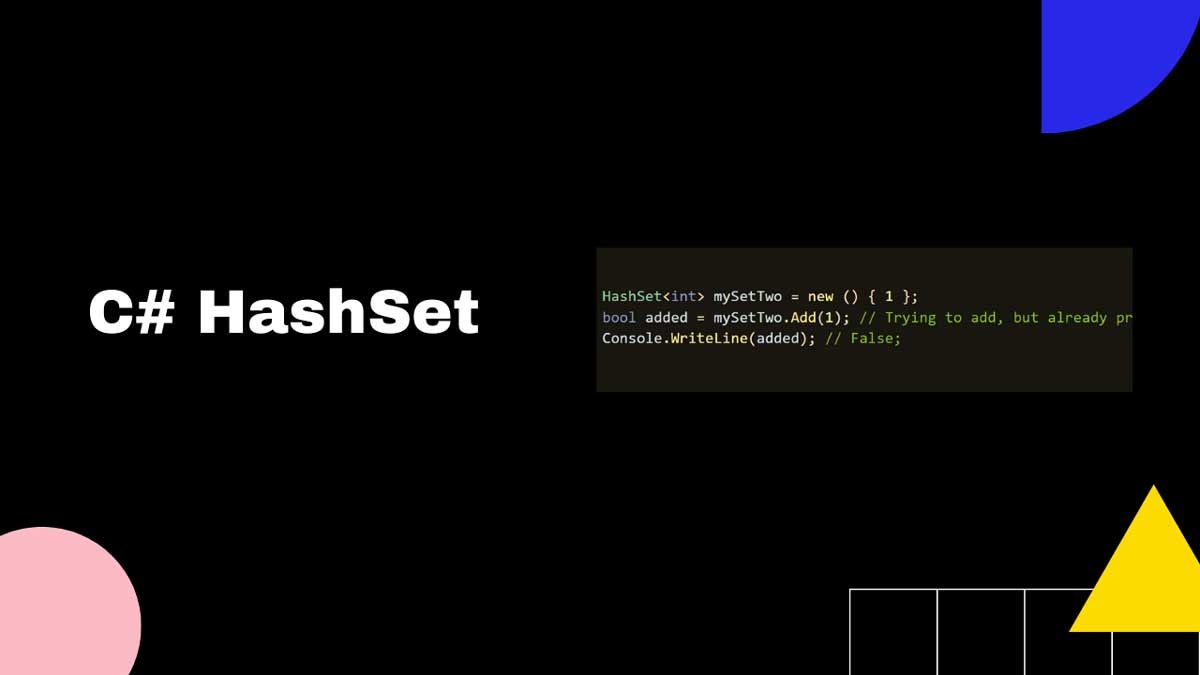
- A HashSet collection is not sorted and cannot have duplicate elements.
- A HashSet has superior performance when compared to other collections because of its intrinsic implementation.
- A HashSet collection is not thread safe, so it should implement a Thread Safe code by using the synchronization techniques.
Key points
When working with HashSet, note that HashSet:
- Stores the values unordered.
- Can add or remove elements, but it performs the best with a fixed length.
- Allows the null values.
- Is serializable because it implements ISerializable interface.
- Doesn't use indices, so the ElementAt method called on a HashSet object with an integer as a parameter will return the element at the specified position.
HashSet usage
To use a HashSet, you must first have an instance of a HashSet.
var set = new HashSet<int>();After you have created an instance of a HashSet , add items to it by adding them one at a time like this:
set.Add(3);You can also add several items to the C# HashSet at once using this syntax:
var set = new HashSet<int> { 1, 2, 3 };To remove specific items from a set, you would use the "Remove" method like this:
set.Remove(3);Make sure to add using System.Collections.Generic at the top of your program.
HashSet performance
| Data Structure | Insert | Remove | Search | Space Used |
|---|---|---|---|---|
| Array | N/A | N/A | O(n) | O(n) |
| List | O(n) | O(n) | O(n) | O(n) |
| Linked List | O(1) | O(1) | O(n) | O(n) |
| Hash Set | O(1) | O(1) | O(1) | O(n) |
The performance of a HashSet is based on a hash function implementation. The time required to access the element in a HashSet is constant, independent of the number of items added to it.
The implementation uses an array for the implementation and integer as a key. The performance of HashSet depends on the load factor that is used by this collection of data structure.
When we don't add or remove elements frequently, a HashSet outperforms other collections.
HashSet methods
Important HashSet methods are:
- Add: Adds the specified element to a HashSet if it is not already present.
- Clear: Removes all elements from a HashSet.
- Contains: Determines whether a HashSet contains an element with the specified value.
Add
The Add() method adds an item to the HashSet but only if the item is not already present in the HashSet.
If the item is already present in the HashSet, this method does nothing and returns false.
Clear
The Clear() method removes all items from the set. It clears the elements, but not the underlying buckets and slots array. To clear the underlying slots and release the memory, we need to call the TrimExcess method immediately after.
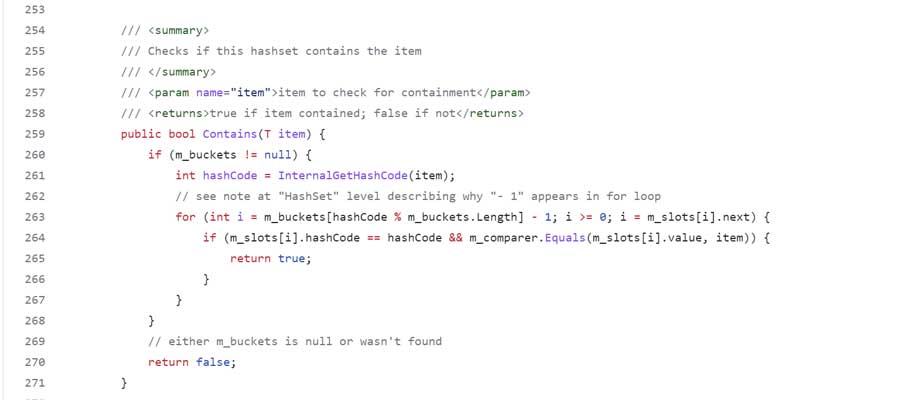
Contains
The Contains() method checks whether a specified element is present in the HashSet. It returns true if an element is found in the set, otherwise false.
HashSet enumeration
In C#, we can enumerate HashSet. HashSet implements the IEnumerable interface. That allows us to use the foreach statement to iterate over a HashSet.
We can also use LINQ to look at the values of a HashSet, or to filter it.
Thread safety
HashSet is not thread safe, so it should implement a Thread Safe code by using the synchronization techniques.
For example, you can use the lock statement to implement thread safety.
You can also use any .NET synchronization primitive for this purpose, such as SemaphoreSlim or ReaderWriterLockSlim.
The following example shows how to implement thread-safe code by using lock keyword:
private readonly ReaderWriterLockSlim _lock = new ReaderWriterLockSlim(LockRecursionPolicy.SupportsRecursion);
private readonly HashSet<T> _hashSet = new HashSet<T>();
#region Implementation of ICollection<T> ...ish
public bool Add(T item)
{
try
{
_lock.EnterWriteLock();
return _hashSet.Add(item);
}
finally
{
if (_lock.IsWriteLockHeld) _lock.ExitWriteLock();
}
}
HashSet vs List
The main difference between HashSet and List is that the list can contain duplicate elements, though both are used to store unique values.
HashSet is much faster than List collection because HashSet lazily initializes underlying data structures.
Hash tables usually contain only a few elements, so the initial capacity is set small — 3 elements.
At the time of adding to HashSet collection, the underlying code compares hash codes, which allows it to group them in buckets. So when you get an item, the underlying code checks it in its respective bucket.
HashSet vs Hashtable
The main difference between HashSet and Hashtable is that the HashSet works with objects while Hashtable has key-value pairs.
The underlying implementation is similar for both because it relies on hash codes. For example, when you add an element to the Hashtable, the implementation adds it into a bucket based on the hash code of the key. If you want to find that element again, the Hashtable will use the hash code of the key to look in only one particular bucket, which makes it easier to find.
HashSet and object equality
For primitive data types, the Object.Equals method returns true if two objects are equal. For example, consider these two int variables:
int num1 = 100;
int num2 = 120;It's easy to tell that 100 is not equal 120.
But for complex objects that we might have in a collection, the Object.Equals method can return false even when two objects are equal in their fields.
For example, consider these two Car objects:
Car car1 = new Car("Honda");
Car car2 = new Car("Honda");By default, using Object.Equals returns false because the two Car object's reference variables are different.
To tell the compiler that these objects are equal, we need to implement the IEquatable interface. This interface lets us override the default Object.Equals method to use our own implementation.
For example:
public class Car: IEquatable<Car>
{
public string Name { get; set; }
public Car(string name)
{
Name = name;
}
public override int GetHashCode()
{
return Name.GetHashCode();
}
public bool Equals(Car other)
{
return this.Name.Equals(other.Name);
}
}
The code above overrides the default Object.Equals method and uses a string's hash code as a way to compare equality between two Car objects.
So now that we have the IEquatable interface implemented, using our new class in a HashSet collection will work.
What is a Hash?
In C#, hash is an integer value that identifies a particular value.
Hash codes are a way to compare two objects to see if they are equal:
- Two equal objects return hash codes that are equal.
- Unequal objects can have identical hash codes.
That's why we use a hash code as a value in a HashSet collection. Comparing the integer value is much faster than comparing two objects using the equals method.
To get the hash code integer value, we can Object.GetHashCode method. Every object has this method.
Conclusion
HashSet is a. NET collection that stores unique elements. Unlike the List, HashSet does not store duplicate elements.
When you add an element to HashSet, it compares hash codes, which allows it group similar items together to save time when looking for an element.
HashSet is faster than List collection because it uses hashing for storage.
HashSet is a superb choice for storing unique elements because it can quickly compare hash codes to group similar items together.
If you are looking for a more efficient way to store and access data in C#, then HashSet should be at the top of your list.
Be careful with the performance of your applications. Always measure and test to ensure that you keep improving it.


Josip Miskovic is a software developer at Americaneagle.com. Josip has 10+ years in experience in developing web applications, mobile apps, and games.
Read more posts →
I've used these principles to increase my earnings by 63% in two years. So can you.
Dive into my 7 actionable steps to elevate your career.